
Introduction to Router LLM
Router LLM is an open-source framework designed to optimize the allocation of computational resources when processing AI prompts. By intelligently routing queries to the most appropriate models based on their complexity, Router LLM can significantly reduce both monetary costs and energy consumption. This innovative approach ensures that high-cost, high-power models are only used when absolutely necessary, while simpler tasks are handled by less expensive, more energy-efficient models.
Monetary Cost Reduction
- Efficient Use of Models:
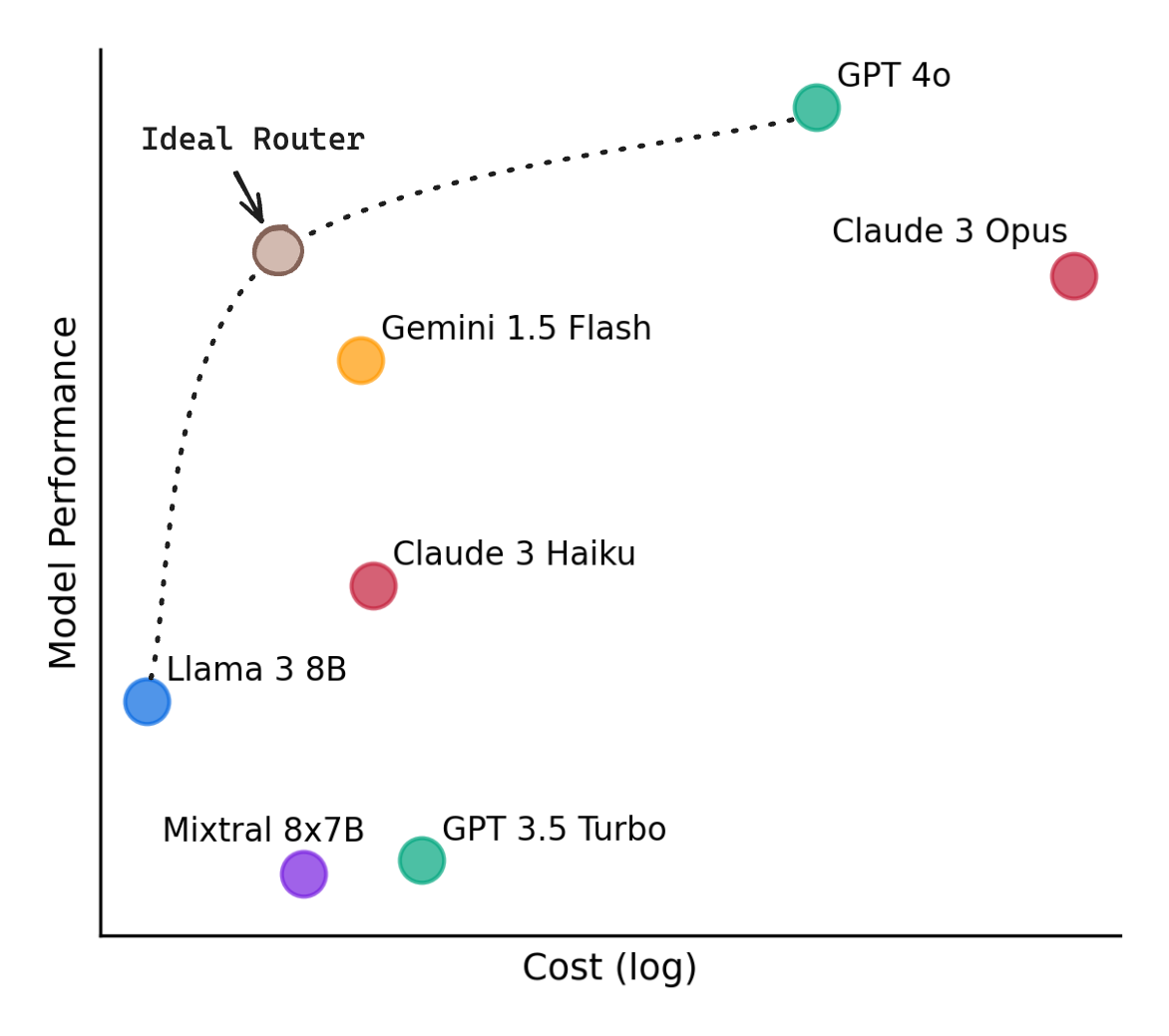
- Router LLM employs a system where each query is initially processed to determine its complexity and requirements. Simple queries that do not require the advanced capabilities of larger, more expensive models are routed to smaller, cheaper models. This ensures that the costliest resources are reserved only for the most demanding tasks.
- Cost-Effective Routing:
- By routing simpler queries to less powerful models, organizations can reduce the frequency with which they need to access high-cost models like GPT-4. This targeted use of resources translates to lower overall expenses because smaller models incur significantly lower operational costs.
- Performance Optimization:
- The framework is designed to maintain high performance levels while minimizing costs. Even though smaller models handle a majority of the queries, the system ensures that the quality of responses remains high, thereby maximizing cost-efficiency without sacrificing performance.
Energy Consumption Reduction
- Local Computation:
- Router LLM prioritizes the use of local models whenever possible. Running models locally on edge devices such as personal computers or smartphones reduces the need for data to be sent to remote servers. This local processing reduces the energy costs associated with data transmission and server operations.
- Reduced Server Load:
- By routing simpler queries to local or less powerful models, Router LLM decreases the demand on centralized, high-power servers. This not only reduces the energy consumption of these servers but also lessens the load on cooling systems that are typically required to manage heat generated by large data centers.
- Optimized Resource Utilization:
- The intelligent routing of queries means that computational resources are used more efficiently. When smaller models handle a significant portion of the workload, the energy consumption per query is reduced. This efficient allocation of resources means that less energy is wasted on over-processing simple tasks.
- Algorithmic Enhancements:
- Techniques such as mixture of agents and Chain of Thought, which are facilitated by Router LLM, can lead to more intelligent and efficient processing of complex queries. These techniques allow models to use tokens more effectively, reducing the overall computational load and, consequently, the energy required for processing.
The Broader Impact
Router LLM's principle of routing queries to the most appropriate model based on their complexity not only reduces the monetary costs associated with using large language models but also significantly cuts down on energy consumption. By leveraging local computation, reducing server load, and optimizing resource utilization, Router LLM makes AI prompting more sustainable and accessible. This dual benefit of cost and energy efficiency is crucial for the widespread adoption and responsible use of AI technologies.
Conclusion
The introduction of Router LLM marks a significant advancement in the field of AI, providing a framework that balances cost, efficiency, and performance. As more organizations and developers adopt this technology, we can expect to see a reduction in the barriers to entry for leveraging powerful AI models. This will not only democratize access to advanced AI capabilities but also promote more sustainable practices in the tech industry.
For those interested in exploring Router LLM further, LMSYS ORG has made the full open-source code base available. This transparency allows developers to experiment with and implement Router LLM in their own projects, pushing the boundaries of what's possible with AI while keeping costs and energy usage in check.
Stay tuned for more updates on this exciting development, and if you want to see a full tutorial on setting up Router LLM, let me know in the comments. If you enjoyed this post, please consider giving it a like and subscribe for more insights into the latest advancements in AI technology.
For a detailed example and further explanation, check out this YouTube video that walks through an implementation of Router LLM: